Over the past two or three years we have seen companies moving towards adopting Scrum or other variations of agile development. I think the main reasons for this has been to give clients more control over the software that is being developed while having the ability to look at the competitors and apply the changes as seen necessary. This is even truer for products that take more than 6 months from conception to delivery.
Back in late 90s – before the dot com bubble burst – anyone who could write simple HTML could quickly write web pages and in the short term hope to make a lot of money. People did not care about the quality of their products as long as they had it out there. But after that bubble burst, with more and more companies failing, companies started to take software development more seriously. One of the things that came out, although it present decades ago, was adoption of rigid waterfall methodology in software development.
Although, waterfall methodology has its own strengths in documentation, strict scheduling and planning and fixed budget, these last two strengths ultimately becomes its weakness as the complexities of projects grow. This problem increases even more so for lengthier projects. With agile on the other hand, while the problems do not just go away, they’re at the very least addressed. For example, instead of defining all the functions today for a product to be delivered 18 months down the road, we will only look at what can be done within the next sprint. It does not mean that the goal of the project is not understood or unimportant. It just means we’re not cramming our developers, architects, project managers and product owners today with what isn’t possible to do. Instead we want to deliver the client the most important part of the project early so if unforeseen changes are necessary, we can do it early. Changes later in the lifecycle of traditional methodologies mean lots of man hours.
Now how agile fits into Atlassian’s products is summed up by two words – “Continuous Integration”. Back in 2010 when I worked on project called Project Management Office Dashboard, I was working on integrating JIRA with the PMO Dashboard with the help of Greenhopper’s remote API. We were using Scrum and we needed to be able to streamline JIRA and PMO so that users could access JIRA from within PMO dashboard. While we were working on this, the other tools came in handy such as Crucible for code review. Code review is one of best practices of agile. If we’re writing code and checking in every couple hours with the help of Bamboo (another Atlassian tool) build server, we sure want the code to be reviewed as frequently even if the builds are successful.
So in brief, adoption of agile and using Atlassian tools go hand-in-hand. In the coming years, I am sure there will be some form of agile development and at least a handful of Atlassian set of tools used by most IT companies all over the globe.

The diary of a lazy developer..
Tuesday, April 9, 2013
Friday, March 1, 2013
Hibernate connection issue with CentOS, MySQL & Tomcat 7
If you are working on CentOS and MySQL, you will want to make sure you verify your connection after the application has been left untouched for some time. Without trying to verify connection you'll end up with a stack trace complaining "Could not open Hibernate Session...". Surprisingly this does not happen on Windows with the same configuration. I am using commons-dbcp.jar and commons-pool.jar. Here is my configuration -
<!-- Define dataSource to use -->
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource">
<property name="driverClassName" value="${hibernate.jdbc.driver}" />
<property name="url" value="${hibernate.jdbc.url}" />
<property name="username" value="${hibernate.jdbc.user}" />
<property name="password" value="${hibernate.jdbc.password}" />
</bean>
<!-- The sessionFactory will scan the domain objects and their annotated relationships. -->
<bean id="sessionFactory" class="org.springframework.orm.hibernate3.annotation.AnnotationSessionFactoryBean">
<property name="dataSource" ref="dataSource" />
<!-- Packages to scan probably works but I will use xml definitions -->
<!--
<property name="packagesToScan">
<list>
<value="com.d2.tej.domain" />
<value="com.d2.tej.dao.impl" />
<value="com.d2.tej.service.impl" />
</list>
</property>
-->
<property name="annotatedClasses">
<list>
<value>com.OrthoPatientDirect.OPDJAR.core.domain.AdminUser</value>
<value>com.OrthoPatientDirect.OPDJAR.core.domain.AdminLogin</value>
<value>com.OrthoPatientDirect.OPDJAR.core.domain.Code</value>
<value>com.OrthoPatientDirect.OPDJAR.core.domain.Patient</value>
<value>com.OrthoPatientDirect.OPDJAR.core.domain.PatientDetail</value>
<value>com.OrthoPatientDirect.OPDJAR.core.domain.PodType</value>
<value>com.OrthoPatientDirect.OPDJAR.core.domain.PodTypeContent</value>
<value>com.OrthoPatientDirect.OPDJAR.core.domain.Practice</value>
<value>com.OrthoPatientDirect.OPDJAR.core.domain.Procedure</value>
<value>com.OrthoPatientDirect.OPDJAR.core.domain.Surgeon</value>
<value>com.OrthoPatientDirect.OPDJAR.core.domain.Subscription</value>
</list>
</property>
<property name="schemaUpdate" value="true" />
<property name="hibernateProperties">
<props>
<prop key="hibernate.connection.isolation">2</prop>
<prop key="hibernate.bytecode.use_reflection_optimizer">true</prop>
<!-- <prop key="hibernate.dialect">org.hibernate.dialect.SQLServerDialect</prop>-->
<prop key="hibernate.dialect">org.hibernate.dialect.MySQLInnoDBDialect</prop>
<!-- org.hibernate.dialect.MySQLMyISAMDialect, org.hibernate.dialect.MySQLDialect, org.hibernate.dialect.MySQLInnoDBDialect -->
<prop key="hibernate.jdbc.batch_size">10</prop>
<prop key="hibernate.max_fetch_depth">2</prop>
<prop key="hibernate.show_sql">true</prop>
<prop key="hibernate.format_sql">true</prop>
<prop key="hibernate.hbm2ddl.auto">update</prop>
<!--connection pool-->
<prop key="hibernate.dbcp.maxActive">10</prop>
<prop key="hibernate.dbcp.whenExhaustedAction">1</prop>
<prop key="hibernate.dbcp.maxWait">20000</prop>
<prop key="hibernate.dbcp.maxIdle">10</prop>
<!-- prepared statement cache-->
<prop key="hibernate.dbcp.ps.maxActive">10</prop>
<prop key="hibernate.dbcp.ps.whenExhaustedAction">1</prop>
<prop key="hibernate.dbcp.ps.maxWait">20000</prop>
<prop key="hibernate.dbcp.ps.maxIdle">10</prop>
<!-- optional query to validate pooled connections:-->
<prop key="hibernate.dbcp.validationQuery">select 1</prop>
<prop key="hibernate.dbcp.testOnBorrow">true</prop>
<prop key="hibernate.dbcp.testOnReturn">true</prop>
</props>
</property>
<!--If you want to configure any listeners for any event this is the place to do. -->
<!--
<property name="eventListeners">
<map>
<entry key="delete">
<bean class="com.tej.core.hibernate.listener.DeleteEventListener" />
</entry>
</map>
</property>
-->
</bean>
<!-- Define dataSource to use -->
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource">
<property name="driverClassName" value="${hibernate.jdbc.driver}" />
<property name="url" value="${hibernate.jdbc.url}" />
<property name="username" value="${hibernate.jdbc.user}" />
<property name="password" value="${hibernate.jdbc.password}" />
</bean>
<!-- The sessionFactory will scan the domain objects and their annotated relationships. -->
<bean id="sessionFactory" class="org.springframework.orm.hibernate3.annotation.AnnotationSessionFactoryBean">
<property name="dataSource" ref="dataSource" />
<!-- Packages to scan probably works but I will use xml definitions -->
<!--
<property name="packagesToScan">
<list>
<value="com.d2.tej.domain" />
<value="com.d2.tej.dao.impl" />
<value="com.d2.tej.service.impl" />
</list>
</property>
-->
<property name="annotatedClasses">
<list>
<value>com.OrthoPatientDirect.OPDJAR.core.domain.AdminUser</value>
<value>com.OrthoPatientDirect.OPDJAR.core.domain.AdminLogin</value>
<value>com.OrthoPatientDirect.OPDJAR.core.domain.Code</value>
<value>com.OrthoPatientDirect.OPDJAR.core.domain.Patient</value>
<value>com.OrthoPatientDirect.OPDJAR.core.domain.PatientDetail</value>
<value>com.OrthoPatientDirect.OPDJAR.core.domain.PodType</value>
<value>com.OrthoPatientDirect.OPDJAR.core.domain.PodTypeContent</value>
<value>com.OrthoPatientDirect.OPDJAR.core.domain.Practice</value>
<value>com.OrthoPatientDirect.OPDJAR.core.domain.Procedure</value>
<value>com.OrthoPatientDirect.OPDJAR.core.domain.Surgeon</value>
<value>com.OrthoPatientDirect.OPDJAR.core.domain.Subscription</value>
</list>
</property>
<property name="schemaUpdate" value="true" />
<property name="hibernateProperties">
<props>
<prop key="hibernate.connection.isolation">2</prop>
<prop key="hibernate.bytecode.use_reflection_optimizer">true</prop>
<!-- <prop key="hibernate.dialect">org.hibernate.dialect.SQLServerDialect</prop>-->
<prop key="hibernate.dialect">org.hibernate.dialect.MySQLInnoDBDialect</prop>
<!-- org.hibernate.dialect.MySQLMyISAMDialect, org.hibernate.dialect.MySQLDialect, org.hibernate.dialect.MySQLInnoDBDialect -->
<prop key="hibernate.jdbc.batch_size">10</prop>
<prop key="hibernate.max_fetch_depth">2</prop>
<prop key="hibernate.show_sql">true</prop>
<prop key="hibernate.format_sql">true</prop>
<prop key="hibernate.hbm2ddl.auto">update</prop>
<!--connection pool-->
<prop key="hibernate.dbcp.maxActive">10</prop>
<prop key="hibernate.dbcp.whenExhaustedAction">1</prop>
<prop key="hibernate.dbcp.maxWait">20000</prop>
<prop key="hibernate.dbcp.maxIdle">10</prop>
<!-- prepared statement cache-->
<prop key="hibernate.dbcp.ps.maxActive">10</prop>
<prop key="hibernate.dbcp.ps.whenExhaustedAction">1</prop>
<prop key="hibernate.dbcp.ps.maxWait">20000</prop>
<prop key="hibernate.dbcp.ps.maxIdle">10</prop>
<!-- optional query to validate pooled connections:-->
<prop key="hibernate.dbcp.validationQuery">select 1</prop>
<prop key="hibernate.dbcp.testOnBorrow">true</prop>
<prop key="hibernate.dbcp.testOnReturn">true</prop>
</props>
</property>
<!--If you want to configure any listeners for any event this is the place to do. -->
<!--
<property name="eventListeners">
<map>
<entry key="delete">
<bean class="com.tej.core.hibernate.listener.DeleteEventListener" />
</entry>
</map>
</property>
-->
</bean>
Saturday, January 19, 2013
5 Steps to Improve Your Java App’s Performance with New Relic
Overview
The New Relic is a must-have tool when it comes to tuning and monitoring your java web application. The plugin is trivial to install on your application server and once your application is deployed and your app server restarted to take effect, you will quickly have access to a very informative dashboard (see Figure 1). Although the New Relic allows you to monitor different stacks – Servers, Applications, Transactions and Real-time user experience monitoring, while all the stacks are equally important, we’ll be focusing on the Application stack. I will also briefly explain the Transactions stack as this is a new feature that fits well for our tuning purpose.
Application Stack - Dashboard view
The Applications stack in the dashboard displays the applications that are deployed. On the right hand side recent events are displayed. These are important as they list out Alert notifications which are based on customizable parameters, Apdex score which is based on application’s throughput and is also customizable, Critical problems such as Error rate, Downtime and any recent activities performed on the dashboard such as updating application settings. Clicking on any of these notifications will allow you to drill down to view detailed, graphical reports. We should now click on the application name (OPD) in order to set performance monitoring parameters and analyze them.
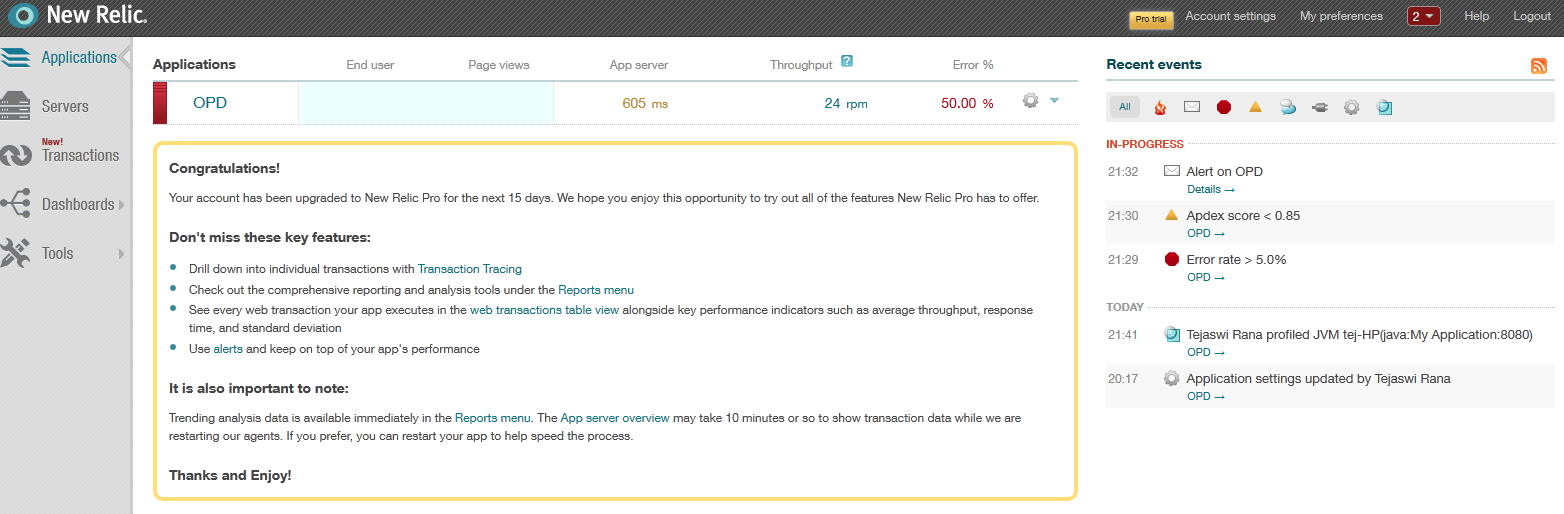
Figure 1: Dashboard View of Sample Web Application – OPD
Tuning the Application
All of our work for this tutorial is managed under the Monitoring tab. The 5 steps we will be focusing on are –
i. Database operations – operations that are most time consuming.
ii. Web transactions – APDEX most dissatisfying.
iii. Profiling JVM – CPU burn broken down by web requests.
iv. External Services - Total Response time of external services.
v. Transactions – Closely monitor ‘key’ web transactions with more precision.
Please note that I have selected only one of the many tuning parameters available on each of the tuning steps. The last step is found under the Transactions stack.
Database Operations – operations that are most time consuming
Probably, the most important area of tuning a web application apart from the code itself is the database. Here we want to look at database operations (Select, Update, Insert, Delete) that are most time consuming. Figure 2 below shows that ‘SELECT’ queries against table ‘patient_detail’ are being made 45% of the time. When we combine this information with the response time and throughput graph on the right, we will be able to flag this. In this instance, the throughput is less than 2ms. So we’re good. Additionally, we can also examine what pages/resources (jsps, filters, interceptors, etc.) are making this database call.
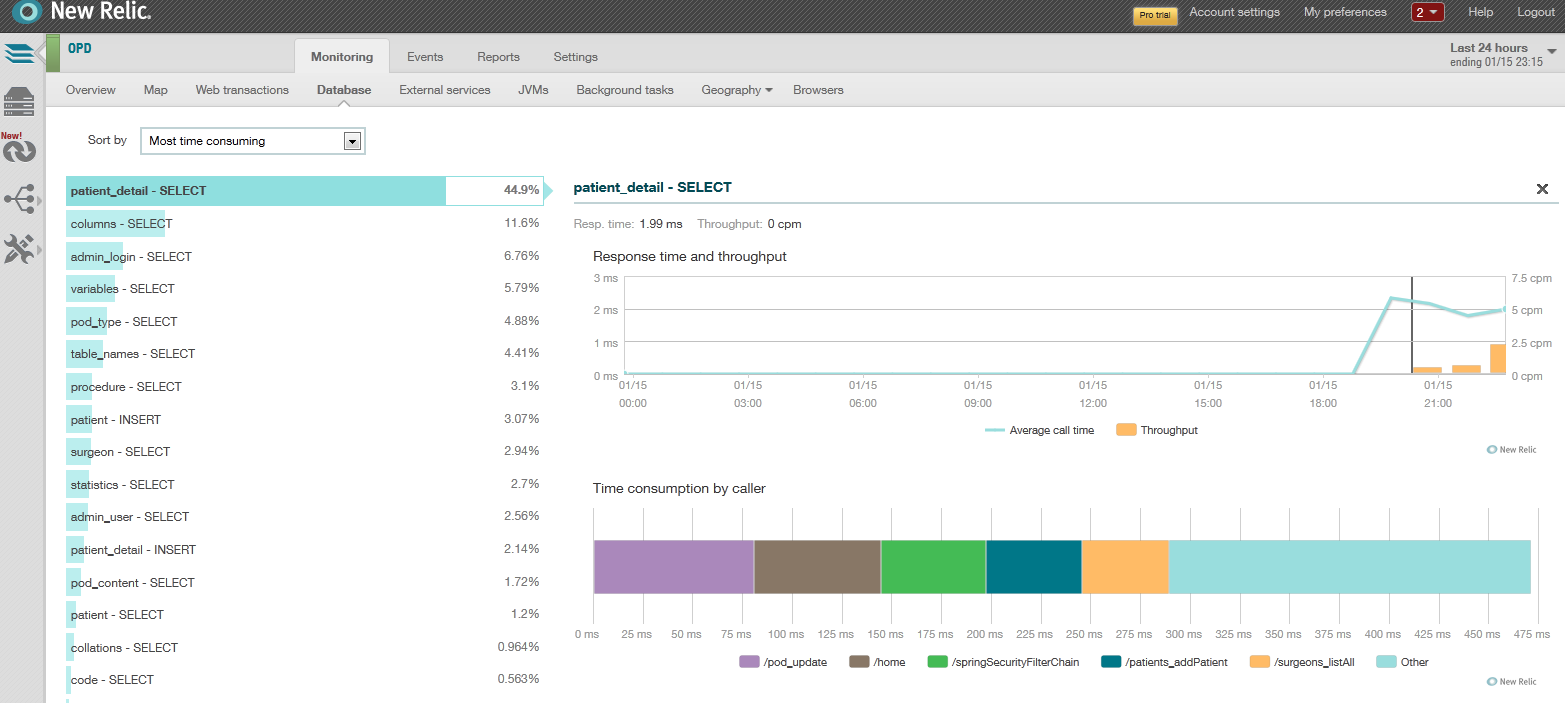
Figure 2: Database Operations sorted by ‘Most time consuming’ filter
Web transactions – APDEX most dissatisfying transactions
APDEX or Application Performance Index takes into account averages of response times of each transaction and gives insight about user satisfaction. This is useful in determining what web transactions are taking exponentially longer than others and resulting in user dissatisfaction. Figure 3 shows that ‘/login’ needs to be looked into immediately as it is consuming 88% of the overall wall clock time. At the bottom right we can see ‘App server transaction traces’ that show two separate instances of request made to ‘/login’ took over 6.5 seconds.

Figure 3: APDEX ‘Most dissatisfying’ web transactions
Profiling JVM – CPU burn broken down by web requests
We can also profile the JVM to look at CPU burn broken down by web requests to view what requests are hogging the CPU. We can then look at that specific part of the code to further examine. Figure 4 displays a sample profile output. There isn’t request that is really hogging the CPU. So we’re good here.

Figure 4: JVM Profiling for CPU burn filtered by Web Requests
External Services - Total Response time of external services
If we have any REST or WS* web service calls or remote messaging, we can view the response times of those external services to see if any of the calls are taking longer than our specified APDEX. To an end user these external services should feel like making a request to any other web transaction. Although our sample application does not make any external service calls, you can easily view these from the ‘External services’ sub tab under the ‘Monitoring’ tab.
Transactions – Closely monitor ‘key’ web transactions with more precision
The new ‘Transactions’ stack allows monitoring of the most important assets of the application. Under the hood this is similar to identifying slow response time for a web transaction. The added benefit of using this is we can view more detailed graph with all the resources associated with the transaction. For example, I’ve created a ‘Security Check’ transaction to monitor the authentication and authorization process of spring security framework. In figure 5, we can see response times of different filters in the filter chain. Notice also the error rate is very high at around 11:45am till noon. We can view the application server’s log for that period of time to see what is going on.

Figure 5: Key Transactions
Summary
All of the steps we took in improving our java application’s performance are only fraction of what we can do with New Relic. Also, the application could easily have been an asp.net application. We can also monitor the server stack in addition to the application stack to get a better picture of how our application(s) make use of the server resources such as I/O, RAM and CPU.
Subscribe to:
Posts (Atom)